Introduction
In the previous examples, we used a Cladogenetic State change Speciation and Extinction (ClaSSE) model (Goldberg and Igić 2012) to investigate the evolution of primates. ClaSSE jointly models character evolution and the birth-death process, incorporating both anagenetic and cladogenetic state changes. The GeoSSE model (Goldberg et al. 2011) is a specific type of ClaSSE model that is explicitely designed for geographic range evolution, with particular model assumptions related to the ways that species spread and split. This tutorial gives a step-by-step explanation of how to perform a GeoSSE analysis in RevBayes. We will model the evolution and biogeography of the South American lizard genus Liolaemus using two regions: Andean, and non-Andean (Esquerré et al. 2019).
NOTE: Although this tutorial is written for a two-region biogeographic analysis, it is designed to be applicable to analyses involving more regions. In general, we anticipate it should perform well for as many as eight regions (255 distinct ranges) or more with additional optimizations.
The GeoSSE model
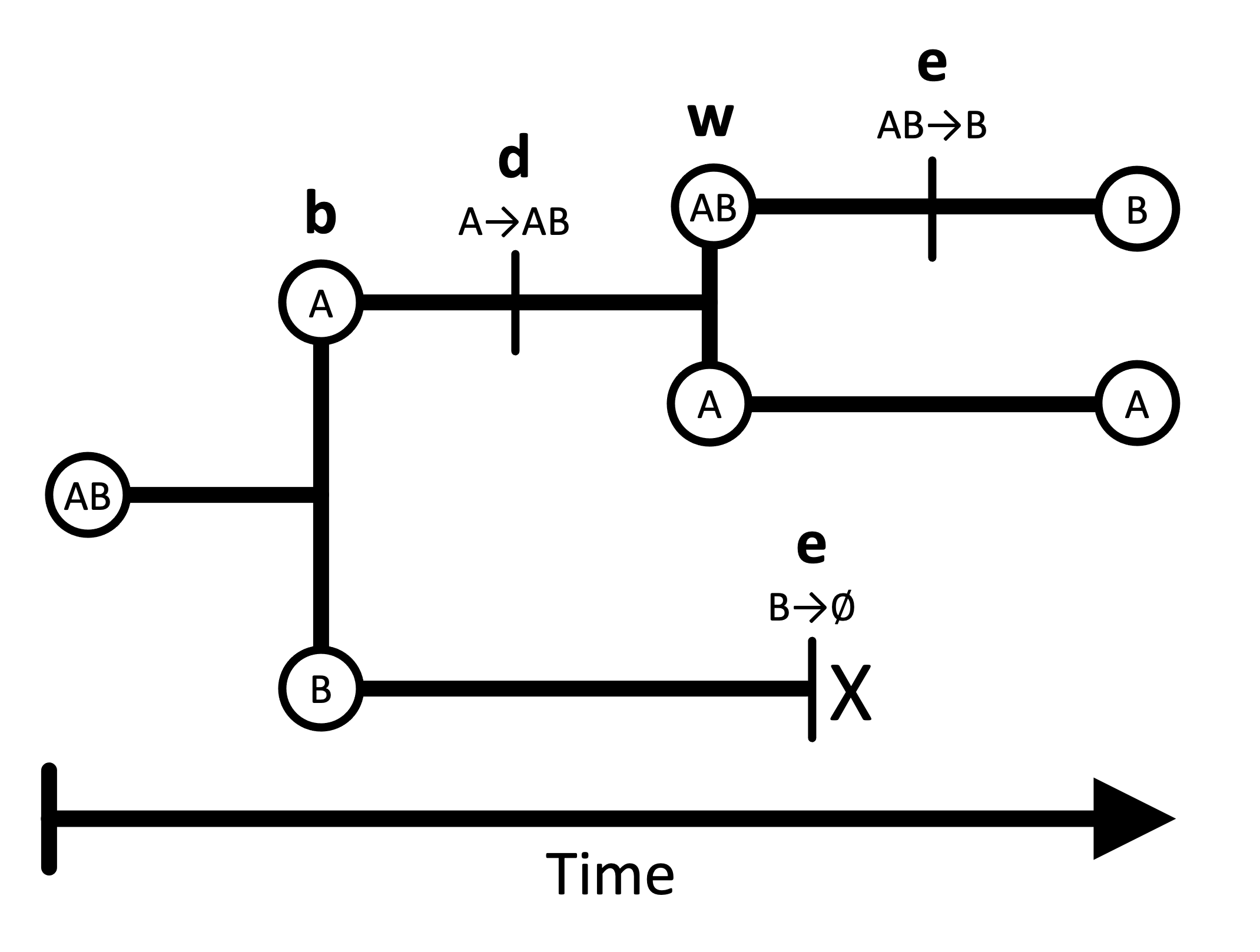
In the GeoSSE model, lineage “states” represent possible geographic ranges, comprised of one or more discrete regions. For example, in a two-region scenario, there are three possible ranges: A, B, and AB. Lineages split and transition between these states according to four core processes: within-region speciation, local extinction (extirpation), between-region speciation, and dispersal. The model is constrained such that a lineage can only experience a single event at any instant in time.
Within- and between-region speciation are cladogenetic processes that create new phylogenetic lineages, which may inherit ranges that differ from the ancestral species. In a within-region speciation event, one daughter lineage inherits the entire ancestral range (which might consist of one or more regions), and the other daughter inherits a single region from the ancestral range. In a between-region speciation event, the widespread ancestral range (of two or more regions) is subdivided and inherited by two new daughter lineages. Between-region speciation rates are always symmetric (separation between A and B is the same as separation between B and A). The standard GeoSSE model does not allow for other kinds of speciation events. For example, an ancestor with a widespread range (of two or more regions) cannot produce daughters that both possess the entire ancestral range (a widespread sympatry scenario).
Extinction and dispersal are anagenetic processes, occurring along the branches of an evolutionary tree. Extinction occurs locally within a single region; there is no separate parameter for global extinction, and lineages can only experience one local extirpation event at a time. Therefore, a widespread lineage can only go extinct by losing each of its regions individually until one remains, then losing that last region. Lineages also disperse by adding individual regions to their ranges, and dispersal rates into a new region are the sum of pairwise dispersal rates from each starting region into the new region.
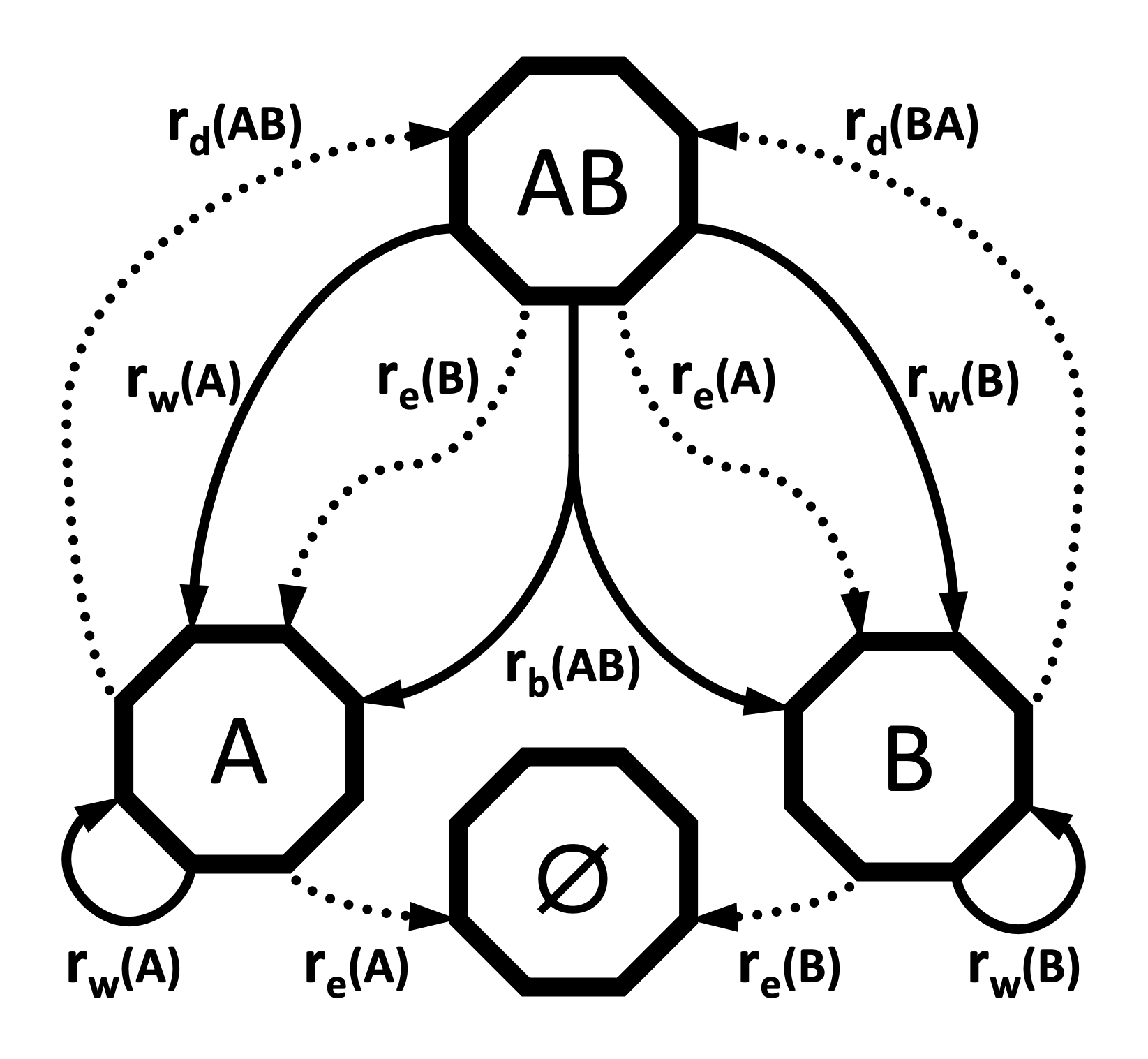
The GeoSSE model allows each region or region pair to possess its own rate for each process. For example, the within-region speciation rate for region A may not necessary equal the within-region speciation rate for region B. Similarly, the dispersal rate from A to B does not necessarily equal the dispersal rate from B to A. When constructing the GeoSSE model, each rate will be represented with its own parameter. We will represent these rates with the following vectors and matrices: $r_w$ for the vector of within-region speciation rates, $r_e$ for the vector of extinction rates, $r_b$ for the matrix of between-region speciation rates, and $r_d$ for the matrix of dispersal rates.
Setup
Important version info!!
This tutorial is the first in a series of lessons explaining how to build increasingly powerful but computationally demanding GeoSSE-type models for biogeographic analyses. Inference under these models is powered by the Tensorphylo plugin for RevBayes, located here: bitbucket.org/mrmay/tensorphylo/src/master (May and Meyer). This tutorial, and following tutorials for GeoSSE-type models, will also require a development version of RevBayes built from the
hawaii_fixbranch (this message will be removed when the branch is merged). As an alternative to building the development version of RevBayes and installing Tensorphylo, you can instead use the RevBayes Docker image, which comes pre-configured with Tensorphylo enabled. The RevBayes Docker tutorial is located here: revbayes.github.io/tutorials/docker.
Running a GeoSSE analysis in RevBayes requires two important data files: a file representing the time-calibrated phylogeny and a biogeographic data matrix describing the ranges for each species. In this tutorial, tree.mcc.tre is a time-calibrated phylogeny of Liolaemus. ranges.nex assigns ranges to each species for a two-region system: an Andean region and a non-Andean region in South America. For each species (row) and region (column), the file reports if the species is present (1) or absent (0) in that region.
If you prefer to run a single script instead of entering each command manually, the RevBayes script called geosse.Rev contains all of the commands that are used in the tutorial. There is also an R script for plotting the analysis results. The data and script can be found in the Data files and scripts box in the left sidebar of the tutorial page. Somewhere on your computer, you should create a directory (folder) for this tutorial. Inside the tutorial directory, you should create a scripts directory. This is the directory where you will run RevBayes commands, or where you will put the geosse.Rev and geosse.R scripts. Then, you should create a data directory inside the tutorial directory, and download the two datafiles to this directory.
GeoSSE in RevBayes
Getting started
After starting up RevBayes from within your local scripts directory, you can load the TensorPhylo plugin. You will need to know where you downloaded the plugin. For example, if you cloned the TensorPhylo directory into your home directory at ~/tensorphylo, you would use the following command to load the plugin:
loadPlugin("TensorPhylo", "~/tensorphylo/build/installer/lib")
Note that if you’re using the RevBayes Docker image, then the Tensorphylo plugin is installed in the / (root) directory:
loadPlugin("TensorPhylo", "/tensorphylo/build/installer/lib")
It is also a good idea to set a seed. If you want to exactly replicate the results of the tutorial, you should use the seed 1.
seed(1)
We also want to tell RevBayes where to find our data (and where to save our output later). If you have set up your tutorial directory in a different way than suggested, you will need to modify the filepaths.
fp = "../"
dat_fp = fp + "data/"
out_fp = fp + "output/"
bg_fn = dat_fp + "ranges.nex"
phy_fn = dat_fp + "tree.mcc.tre"
Data
Next, we will read in the data. Let’s start with the phylogenetic tree.
phy <- readTrees(phy_fn)[1]
In order to set up our analysis, we will want to know some information about this tree: the root age, the taxa and their names, and the number of taxa.
tree_height <- phy.rootAge()
taxa = phy.taxa()
num_taxa = taxa.size()
We also want to read in the range data.
bg_01 = readDiscreteCharacterData(bg_fn)
We want to get some information about this range data: how many regions there are, how many ranges can be constructed from these regions, and how many region pairs there are.
num_regions = bg_01.nchar()
num_ranges = abs(2^num_regions - 1)
num_pairs = num_regions^2 - num_regions
Finally, we want to format the range data to be used in a GeoSSE analysis. This will take the binary range data and output integer states. Note that the integers used to represent ranges are first sorted by range size, then sorted by range patterns given each size-class, following general format of the table in the Introduction to Phylogenetic Models of Discrete Biogeography tutorial.
bg_dat = formatDiscreteCharacterData(bg_01, format="GeoSSE", numStates=num_ranges)
Model setup
In the GeoSSE model, there are four processes: within-region speciation, extinction, between-region speciation, and dispersal. For each process, each possible event its own event rate that depends on the involved regions or region pairs. This will result in two rate vectors r_w and r_e with lengths equal to the number of regions, and two square rate matrices r_b and r_d with a number of entries equal to the number of region pairs. We will construct the event rates by multiplying the region- or pair-specific relative rate parameters in m_x for each event class $x \in { w, e, b, d}$ against the appropriate base rate parameter rho_x to produce the absolute rates r_x. All rho_x parameters will be drawn from the exponential distribution dnExp(1). We will use Dirichlet distributions to generate relative rates.
We will set up within-region speciation rates first.
rho_w ~ dnExp(1)
m_w_simplex ~ dnDirichlet(rep(1,num_regions))
m_w := m_w_simplex * num_regions
r_w := rho_w * m_w
To obtain our vector of relative rates, m_w, we first create the simplex m_w_simplex which is a vector containing num_regions random values that will be estimated, where each value is between 0 and 1 and all values sum to 1. The Dirichlet(1) distribution assigns equal probability to any combination of values in the simplex, making it a “flat prior”. Setting the alpha value to be large sets higher prior probability on relative rates being similar to one another. We design the model in this way so that users can better control how relative rates of within-region speciation are distributed among regions. We then multiply m_w_simplex by num_regions to produce the mean relative rate value of 1 for any region represented in the resulting relative rate vector, m_w. Lastly, we multiply these relative rates by the absolute scaling factor, rho_w, to obtain our vector of absolute rates, r_w.
Extinction rates are set up similarly. The same general logic applies as before. However, these rates are applied only to extinction and not to within-region speciation.
rho_e ~ dnExp(1)
m_e_simplex ~ dnDirichlet(rep(1,num_regions))
m_e := m_e_simplex * num_regions
r_e := rho_e * m_e
From these extinction rates (which are actually single-region extinction rates), we will set up global extinction rates for each possible range in the state space. In the GeoSSE model, lineage-level extincion events occur when a species goes globally extinct (i.e. it loses the last region from its range). Therefore, we will assign all multi-region ranges an extinction rate of 0, and we will assign all single-region ranges an extinction rate equal to the local extirpation rate. Note, ranges are numbered such that indices 1, 2, through num_regions correspond to ranges that respectively contain only region 1, region 2, up through the last region in the system.
for (i in 1:num_ranges) {
mu[i] <- 0.0
if (i <= num_regions) {
mu[i] := r_e[i]
}
}
For between-region speciation, we want to assign rates to each region pair. However, we want these rates to be symmetric, so we only want num_pairs/2 unique values. The same value will be assigned to m_b[i][j] as m_b[j][i]. We can do this by creating an initial simplex from a Dirichlet distribution, and assigning successive values from this simplex as we traverse the m_b matrix.
rho_b ~ dnExp(1)
m_b_simplex ~ dnDirichlet(rep(1,num_pairs/2))
m_b_idx = 1
for (i in 1:num_regions) {
m_b[i][i] <- 0.0
for (j in 1:num_regions) {
if (i < j) {
m_b[i][j] := abs(m_b_simplex[m_b_idx] * num_pairs)
m_b[j][i] := abs(m_b_simplex[m_b_idx] * num_pairs)
m_b_idx += 1
}
r_b[i][j] := rho_b * m_b[i][j]
}
}
For a two-region system with just one pair of regions, m_b_simplex will contain only a single relative-rate factor with the value of 1. That means the value of r_b for between-region speciation is driven entirely by rho_b. However, when the code is used for analyses with num_regions > 2, the simplex m_b_simplex will contain different values. By allowing these values to vary, we allow widespread ranges to split into daughter ranges at different rates depending on the resulting split. These rates are computed using a range-split score (Landis et al. 2022), which we will not cover in this tutorial (RevBayes will complete this calculation automatically).
Finally, for dispersal rates, we want to assign rates to each region pair. These rates are allowed to be asymmetric, so we need num_pairs unique values.
rho_d ~ dnExp(1)
m_d_simplex ~ dnDirichlet(rep(1,num_pairs))
m_d_idx = 1
for (i in 1:num_regions) {
m_d[i][i] <- 0.0
for (j in 1:num_regions) {
if (i != j) {
m_d[i][j] := abs(m_d_simplex[m_d_idx++] * num_pairs)
}
r_d[i][j] := rho_d * m_d[i][j]
}
}
From these rates, we can use RevBayes functions to construct the rate matrices used by the analysis. The first is an anagenetic rate matrix, which gives rates of anagenetic processes. We are not restricting the number of regions that a species can live in at any given time, so we set the maxRangeSize equal to the number of regions. Settings maxRangeSize may be used to reduce the number of range patterns in the model, particularly when num_regions is large.
Q_bg := fnBiogeographyRateMatrix(
dispersalRates=r_d,
extirpationRates=r_e,
maxRangeSize=num_regions
)
We also construct a cladogenetic event matrix, describing the absolute rates of different cladogenetic events. We are not restricting the sizes of ‘split’ subranges following between-region speciation, so we set the max_subrange_split_size equal to the number of regions. From this matrix, we can obtain the total speciation rates per state, as well as a cladogenetic probability matrix.
clado_map := fnBiogeographyCladoEventsBD(
speciation_rates=[rho_w,rho_b],
within_region_features=m_w,
between_region_features=m_b,
max_range_size=num_regions,
max_subrange_split_size=num_regions
)
lambda := clado_map.getSpeciationRateSumPerState()
omega := clado_map.getCladogeneticProbabilityMatrix()
Lastly, we need to assign a probability distribution to range of the most recent common ancestor of all species, prior to the first speciation event. In this analysis, we will assume all ranges were equally likely for that ancestor.
pi_base <- rep(1,num_ranges)
pi <- simplex(pi_base)
With all of the rates constructed, we can create a stochastic variable drawn from this GeoSSE model with state-dependent birth, death, and speciation processes. This establishes how the various processes interact to generate a tree with a topology, divergence times, and terminal taxon states (ranges). Then we can clamp the variable with the fixed tree and present-day range states, allowing us to infer model parameters based on our observed data.
We will use the dnGLHBDSP distribution that interfaces with the Tenorsphylo plugin to model a Generalized Lineage Heterogeneous Birth Death Sampling Process, which is a generalized model (as the name suggests) that can express simpler models, such as GeoSSE models.
Although most of the model variable arguments provided to construct the timetree variable have been described above, we pass a few additional arguments to define how we compute the model likelihood. First, we instruct the model to condition on the process evolving for tree_height units of time by setting condition="time". Alternatively, condition can be used to condition on the process e.g. producing a given number of taxa or surviving until the present (producing >2 taxa). Second, we permit Tensorphylo to use four processors with nProc=4 to speed up computation.
timetree ~ dnGLHBDSP(
rootAge = tree_height,
lambda = lambda,
mu = mu,
eta = Q_bg,
omega = omega,
pi = pi,
condition = "time",
taxa = taxa,
nStates = num_ranges,
nProc = 4
)
timetree.clamp(phy)
timetree.clampCharData(bg_dat)
MCMC
For this analysis, we will perform a short MCMC of 1000 generations, with 100 generations of hyperparameter-tuning burnin. An analysis of this length may not achieve convergence, so these settings should only be used for testing purposes. You can alter this MCMC by changing the number of iterations, the length of the burnin period, or the move schedule. We will also set up the MCMC to record every 10 iterations.
n_gen = 1000
n_burn = n_gen/10
printgen = 10
We want MCMC to update all of the base rate rho parameters, as well as the relative rate Dirichlet simplexes. We will use a scaling move for the base rates, since they should always have positive values. These moves will each be performed once per iteration. Simplexes have a unique kind of move in RevBayes. Instead of performing one simplex move per generation, we will make the number of moves per iteration equal to the number of elements in the simplex.
mvi = 1
mv[mvi++] = mvScale(rho_w, weight=1)
mv[mvi++] = mvScale(rho_e, weight=1)
mv[mvi++] = mvScale(rho_b, weight=1)
mv[mvi++] = mvScale(rho_d, weight=1)
mv[mvi++] = mvSimplex(m_e_simplex, weight=m_e.size())
mv[mvi++] = mvSimplex(m_w_simplex, weight=m_w.size())
mv[mvi++] = mvSimplex(m_b_simplex, weight=m_b_simplex.size())
mv[mvi++] = mvSimplex(m_d_simplex, weight=m_d_simplex.size())
We also want MCMC to keep track of certain things while it runs. We want it to print some output to the screen so we can see how it is running (mnScreen). We also want it to save model parameters to a file (mnModel). Finally, if we want to use the output for ancestral state reconstruction, we want to save states and stochastic character mappings (mnJointConditionalAncestralStates and mnStochasticCharacterMap). All of the output files will be saved in the output directory so that it can be accessed later.
mni = 1
mn[mni++] = mnScreen(printgen=printgen)
mn[mni++] = mnModel(printgen=printgen, filename=out_fp+"model.log")
mn[mni++] = mnJointConditionalAncestralState(glhbdsp=timetree, tree=timetree, printgen=printgen, filename=out_fp+"states.log", withTips=true, withStartStates=true, type="NaturalNumbers")
mn[mni++] = mnStochasticCharacterMap(glhbdsp=timetree, printgen=printgen, filename=out_fp+"stoch.log")
Then we can start up the MCMC. It doesn’t matter which model parameter you use to initialize the model, so we will use m_w. RevBayes will find all the other parameters that are connected to m_w and include them in the model as well. Then we create an MCMC object with the moves, monitors, and model, add burnin, and run the MCMC.
mdl = model(m_w)
ch = mcmc(mv, mn, mdl)
ch.burnin(n_burn, tuningInterval=10)
ch.run(n_gen)
After the MCMC analysis has concluded, we can summarize the ancestral states we obtained, creating an ancestral state tree. This tree will be written to the file ase.tre. It may take a little while.
f_burn = 0.2
x_stoch = readAncestralStateTrace(file=out_fp+"stoch.log")
x_states = readAncestralStateTrace(file=out_fp+"states.log")
summarizeCharacterMaps(x_stoch,timetree,file=out_fp+"events.tsv",burnin=f_burn)
state_tree = ancestralStateTree(tree=timetree,
ancestral_state_trace_vector=x_states,
include_start_states=true,
file=out_fp+"ase.tre",
summary_statistic="MAP",
reconstruction="marginal",
burnin=f_burn,
nStates=3,
site=1)
writeNexus(state_tree,filename=out_fp+"ase.tre")
Output
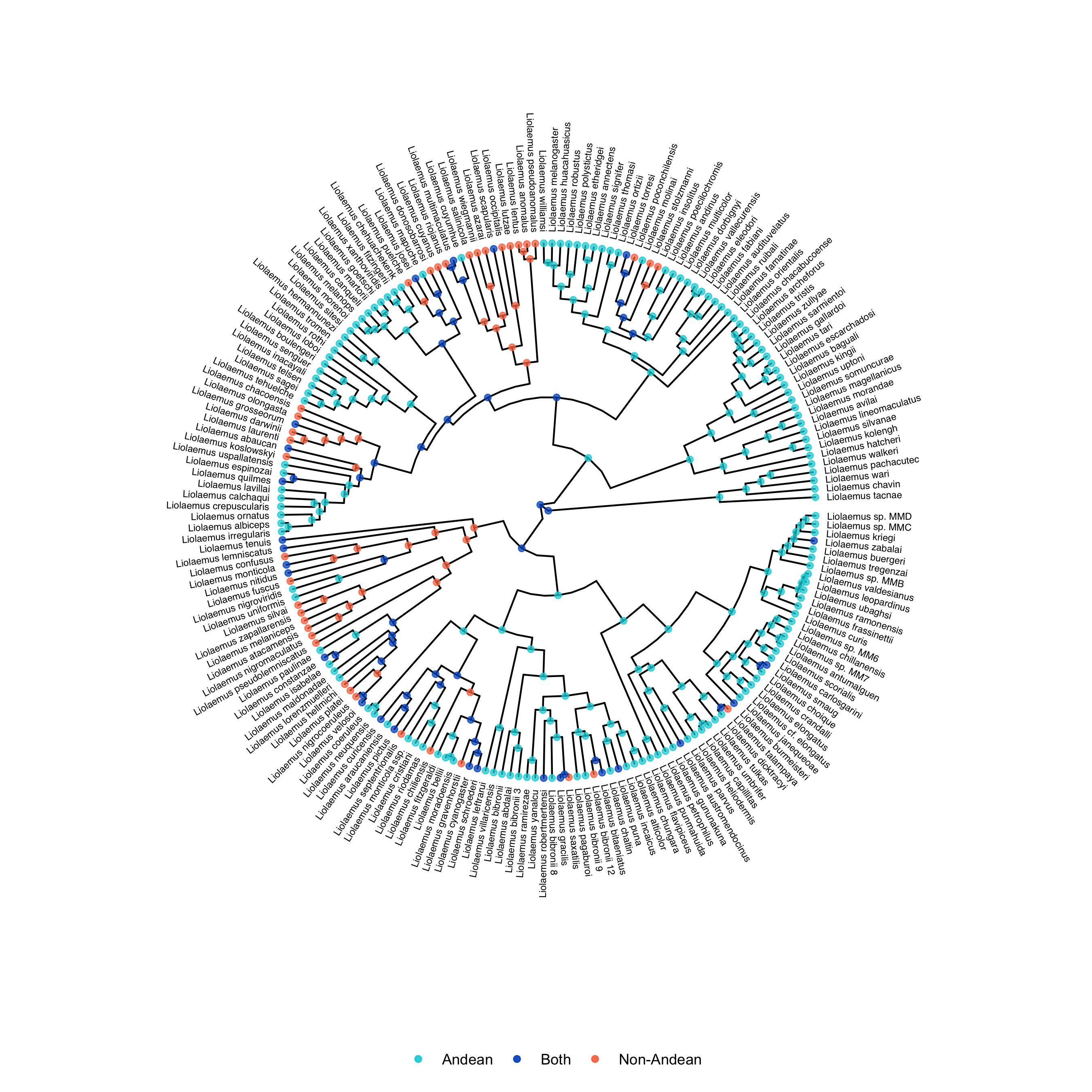
One interesting thing we can do with the output of the GeoSSE analysis is plot ancestral states. This can be done using RevGadgets, an R packages that processes RevBayes output. You can use R to generate a tree with ancestral states by running the geosse.R script, or by executing the following code in R. You can also examine the output files, like model.log, to assess the relative rates of different processes occurring in different regions.
library(RevGadgets)
library(ggplot2)
tree_file = "../output/ase.tre"
output_file = "../output/states.png"
states <- processAncStates(tree_file, state_labels=c("0"="Andean", "1"="Non-Andean", "2"="Both"))
plotAncStatesMAP(t=states,
tree_layout="circular",
node_size=1.5,
node_size_as=NULL) +
ggplot2::theme(legend.position="bottom",
legend.title=element_blank())
ggsave(output_file, width = 9, height = 9)
- Esquerré D., Brennan I.G., Catullo R.A., Torres-Pérez F., Keogh J.S. 2019. How mountains shape biodiversity: The role of the Andes in biogeography, diversification, and reproductive biology in South America’s most species-rich lizard radiation (Squamata: Liolaemidae). Evolution. 73:214–230. 10.1111/evo.13657
- Goldberg E.E., Lancaster L.T., Ree R.H. 2011. Phylogenetic Inference of Reciprocal Effects between Geographic Range Evolution and Diversification. Systematic Biology. 60:451–465. 10.1093/sysbio/syr046
- Goldberg E.E., Igić B. 2012. Tempo and Mode in Plant Breeding System Evolution. Evolution. 66:3701–3709. 10.1111/j.1558-5646.2012.01730.x
- Landis M.J., Quintero I., Muñoz M.M., Zapata F., Donoghue M.J. 2022. Phylogenetic inference of where species spread or split across barriers. Proceedings of the National Academy of Sciences. 119.
- May M.R., Meyer X. TensorPhylo. . https://bitbucket.org/mrmay/tensorphylo/src/master/